PhraseVAE and PhraseLDM: Latent Diffusion for Full-Song Multitrack Symbolic Music Generation
Links: [ Paper ] | [ Code ] | [ Citation ]
Abstract: This technical report presents a new paradigm for full-song symbolic music generation. Existing symbolic models operate on note-attribute tokens and suffer from extremely long sequences, limited context length, and weak support for long-range structure. We address these issues by introducing PhraseVAE and PhraseLDM, the first latent diffusion framework designed for full-song multitrack symbolic music. PhraseVAE compresses an arbitrary variable-length polyphonic note sequence into a single compact 64-dimensional phrase-level latent representation with high reconstruction fidelity, allowing a well-structured latent space and efficient generative modeling. Built on this latent space, PhraseLDM generates an entire multi-track song in a single pass without any autoregressive components. The system eliminates bar-wise sequential modeling, supports up to 128 bars of music (8 minutes at 64 bpm), and produces complete songs with coherent local texture, idiomatic instrument patterns, and clear global structure. With only 45M parameters, our framework generates a full song within seconds while maintaining competitive musical quality and generation diversity. Together, these results show that phrase-level latent diffusion provides an effective and scalable solution to long-sequence modeling in symbolic music generation. We hope this work encourages future symbolic music research to move beyond note-attribute tokens and to consider phrase-level units as a more effective and musically meaningful modeling target.
Demos
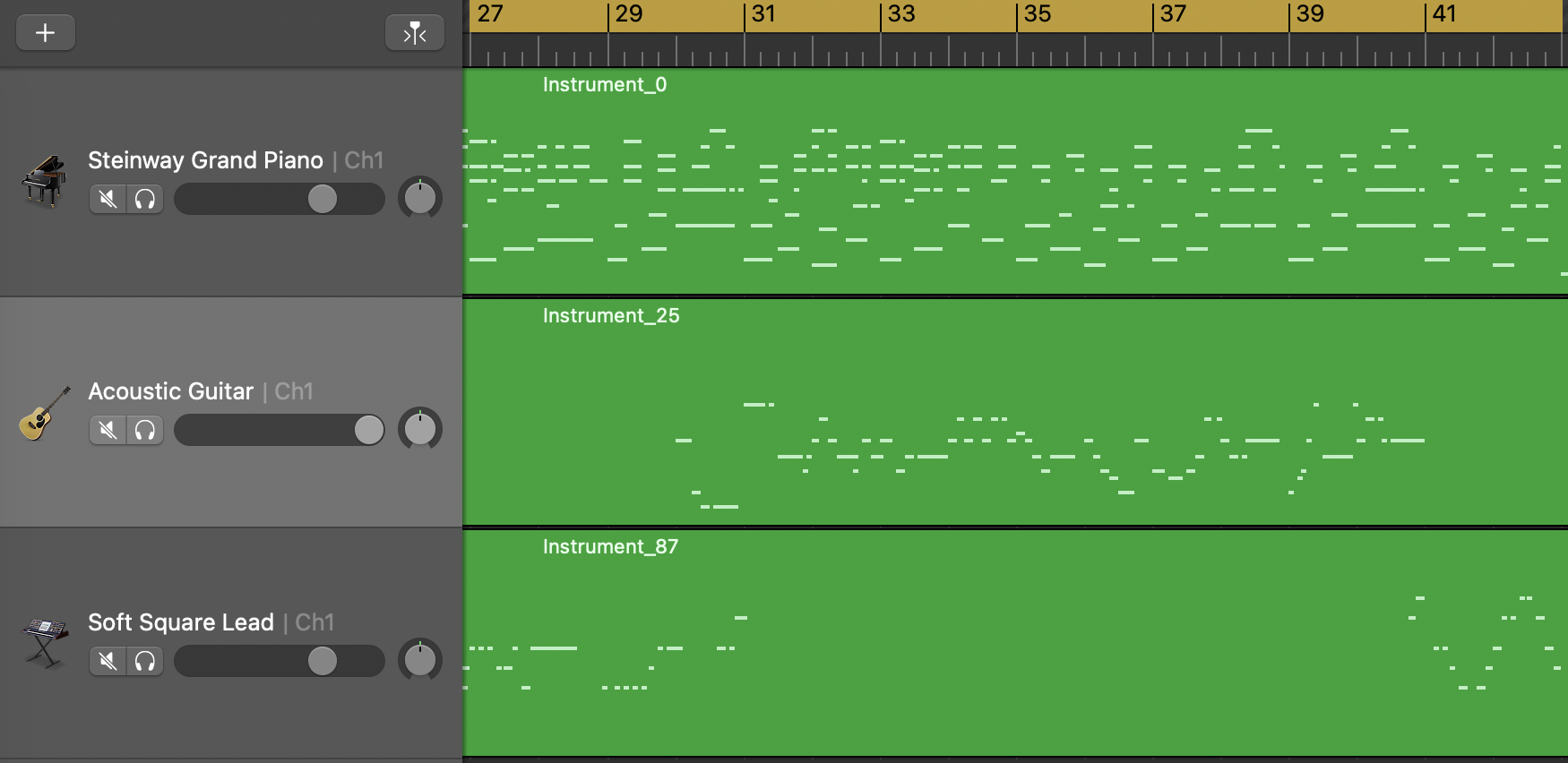
Here are some generation examples from our models. The model is trained with a 3-track pop music dataset (POP909), the training set size is around 800 songs.
Table of Contents:
You can also download all generated samples collected throughout the entire course of the project, for both VAE and LDM, without cherry-picking.
Full Song Generation Results
Below we present a random subset of LDM generations (no cherry-picking).
Unconditional Model
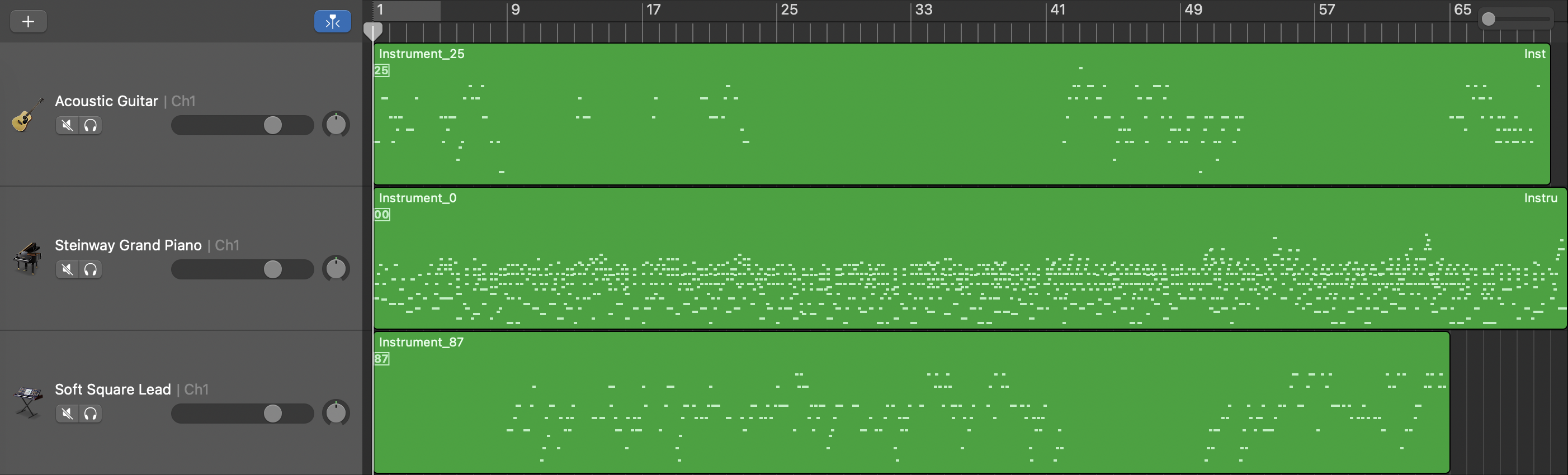
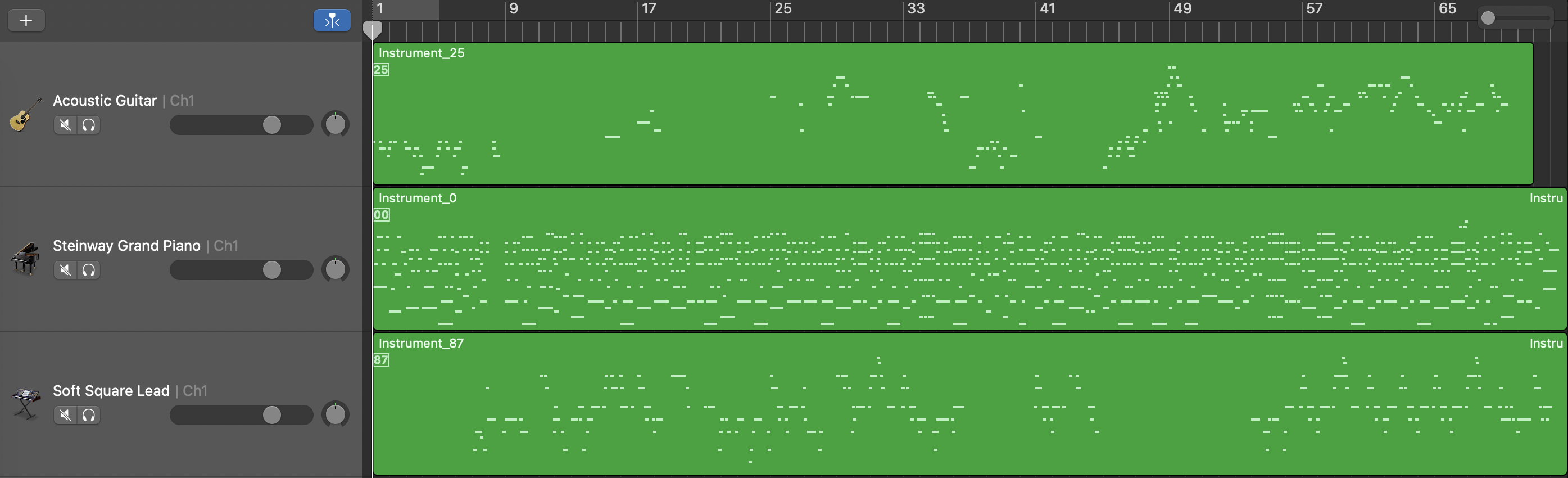
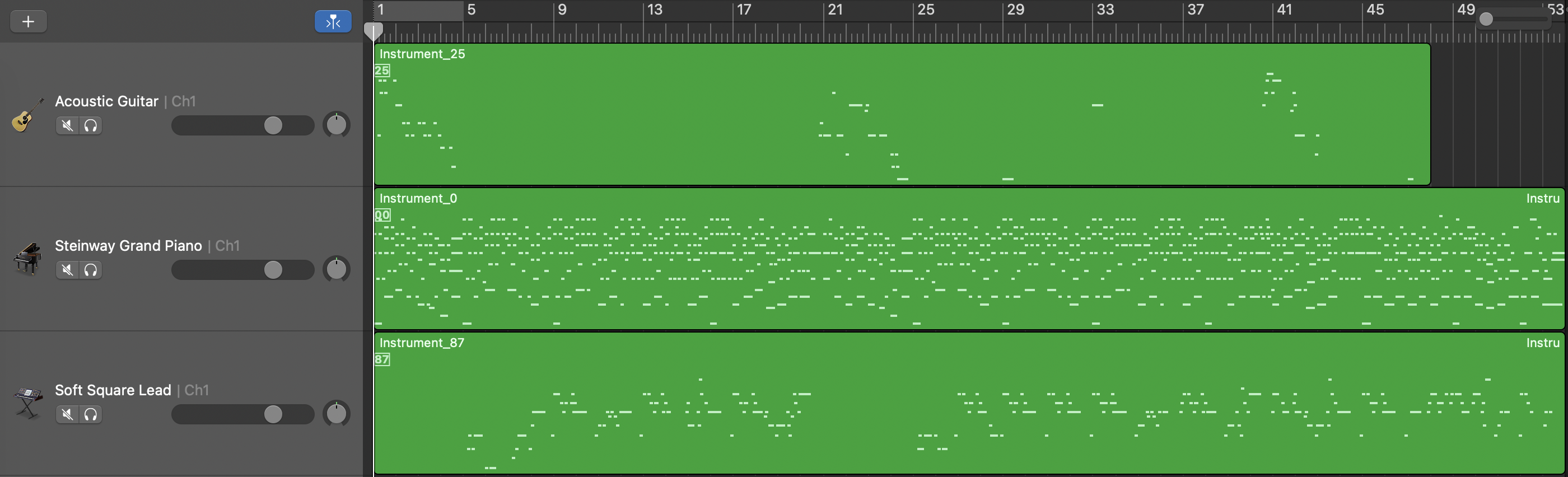
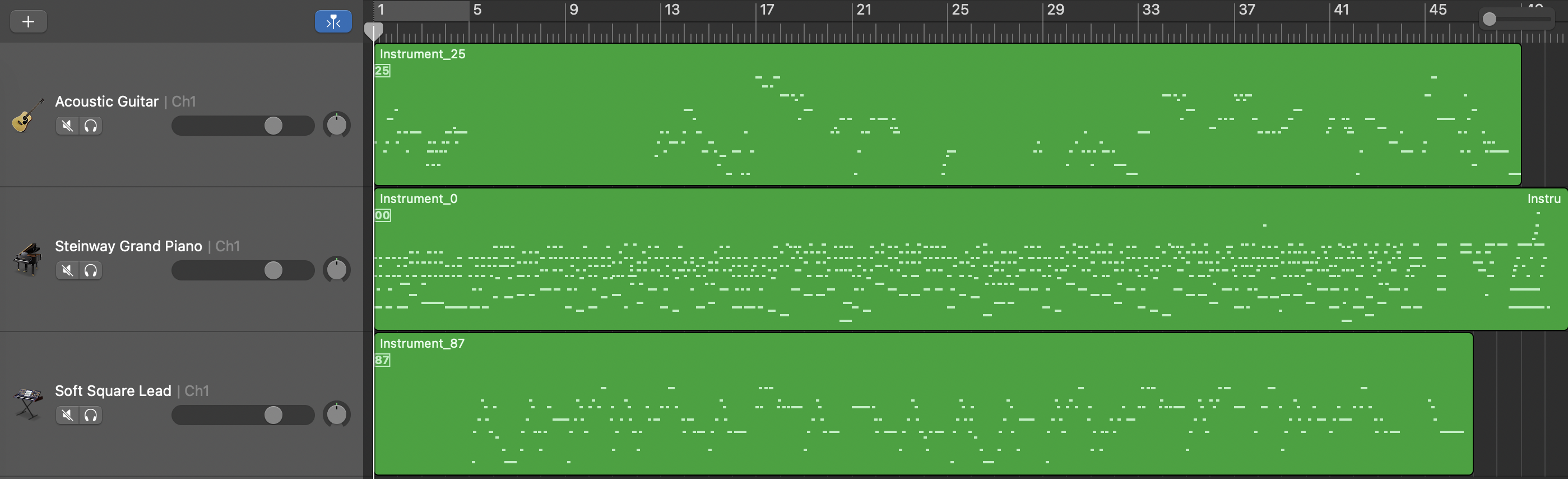
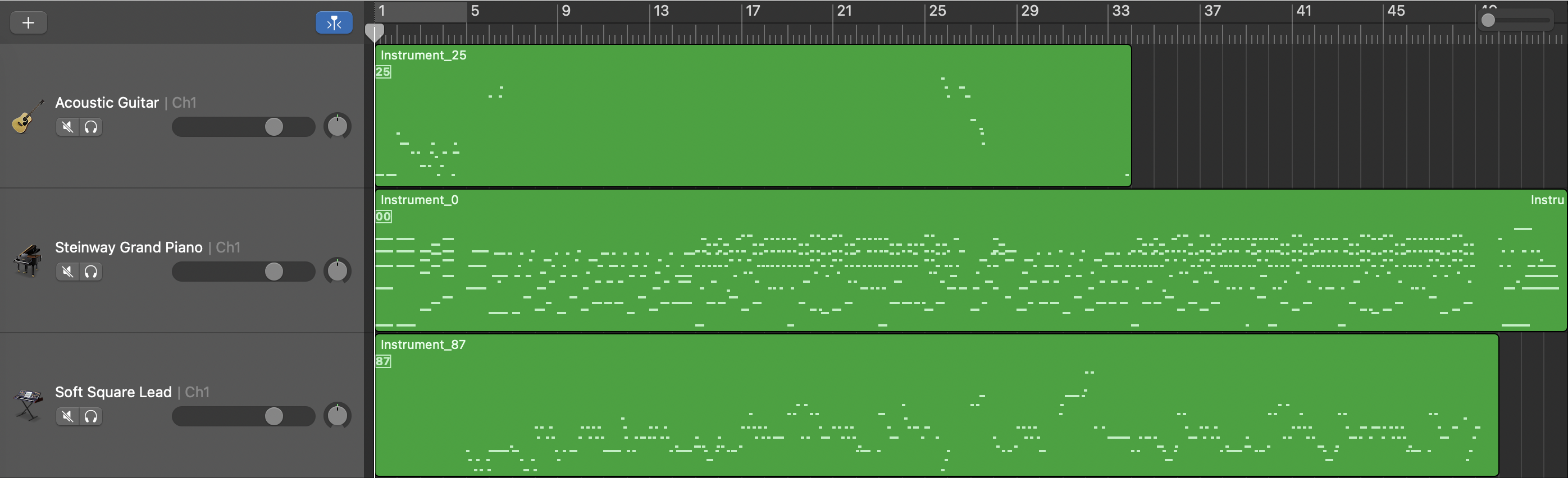
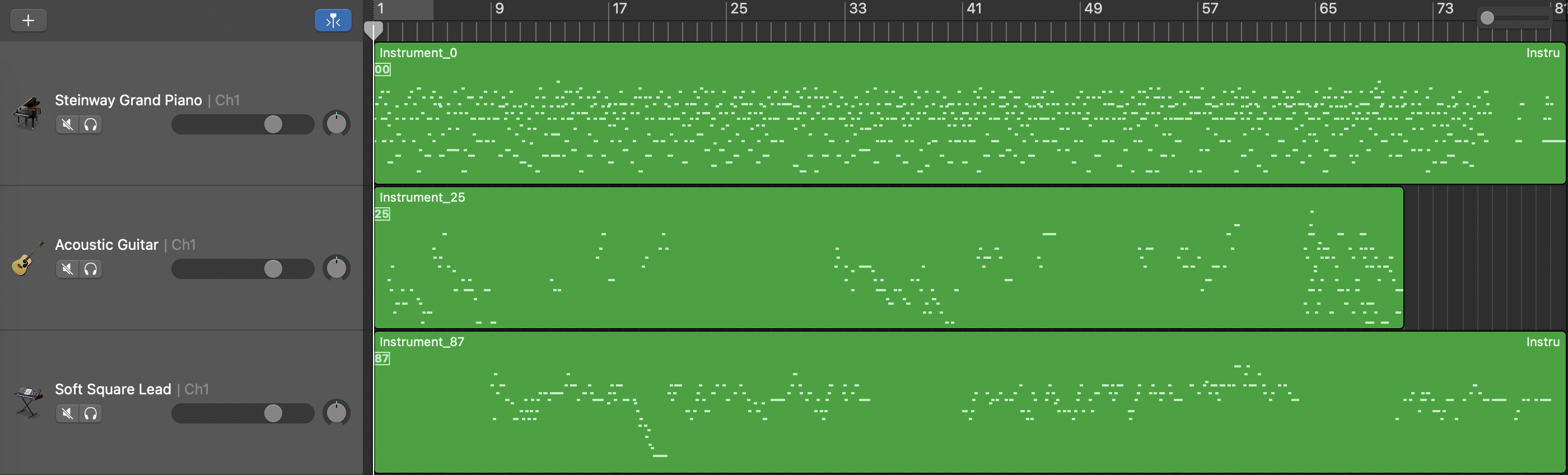
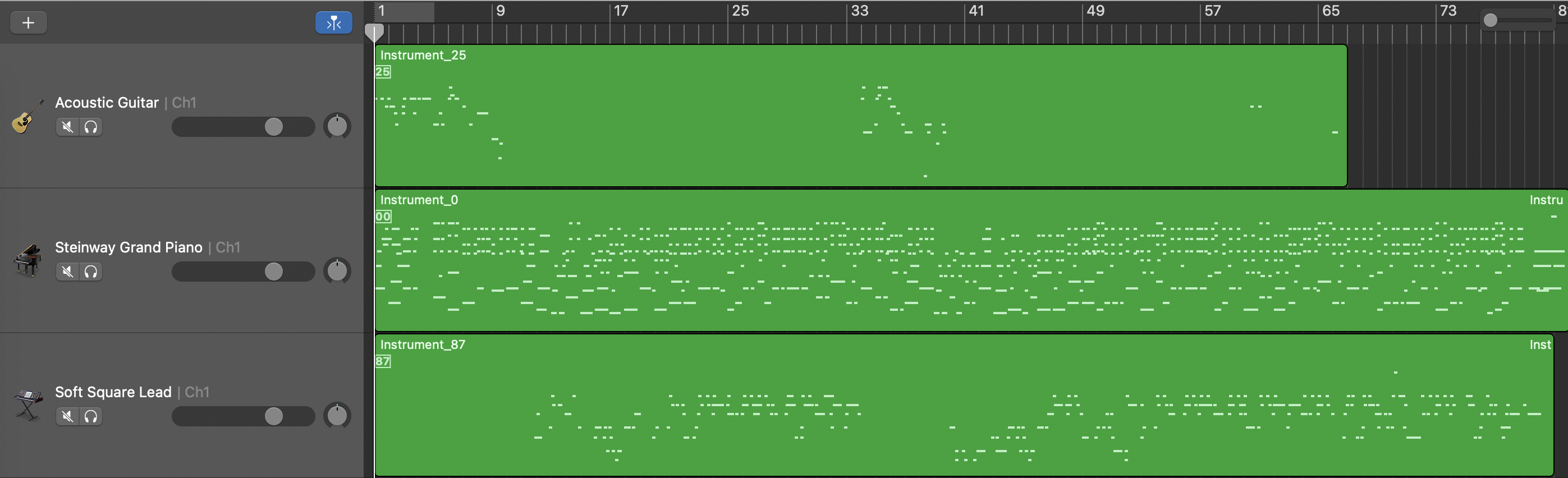

Length Conditioned Model

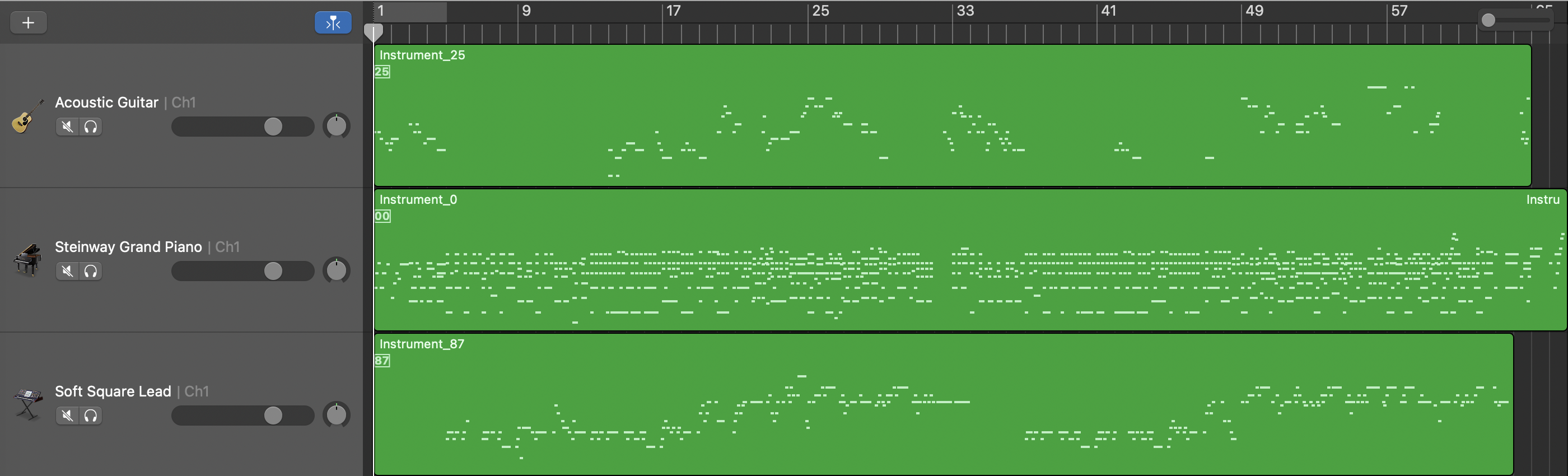
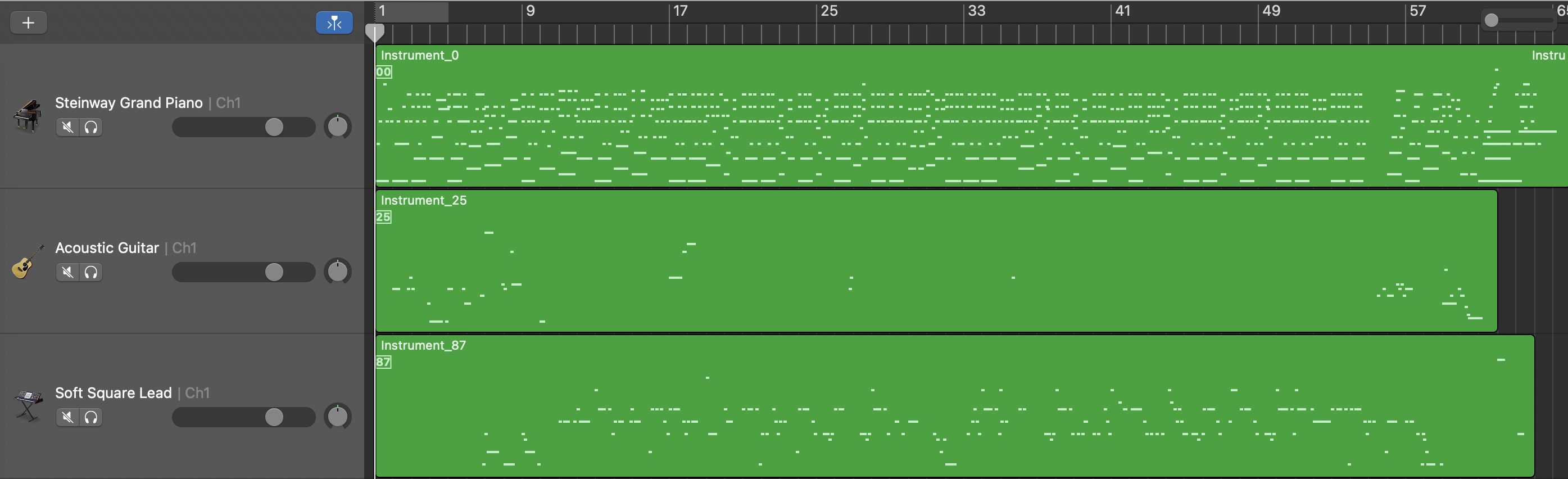
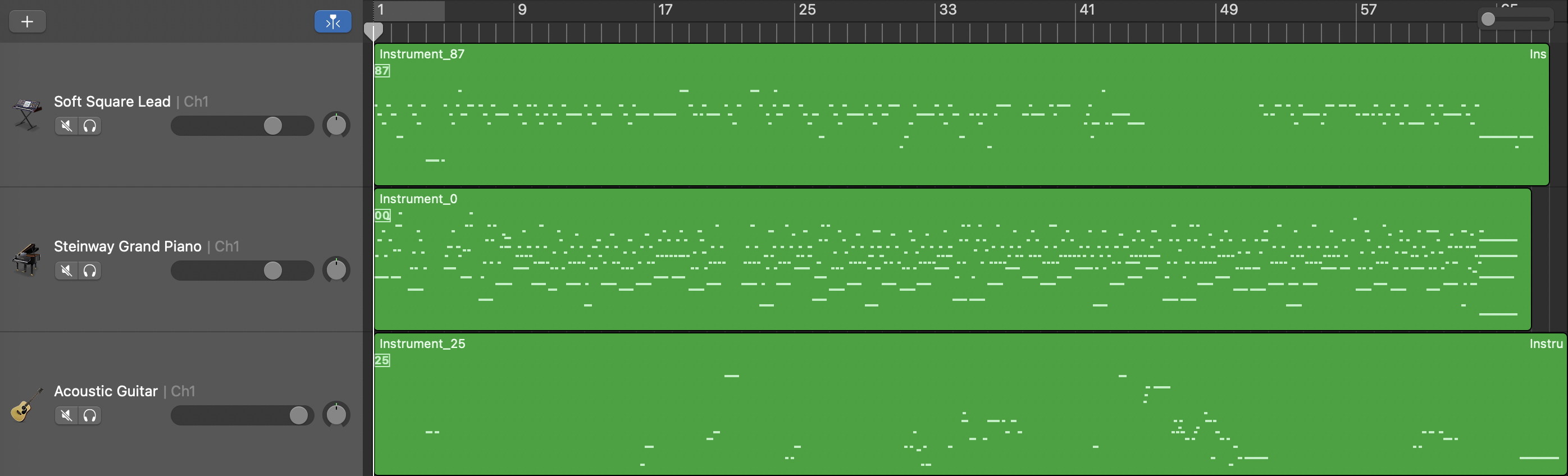


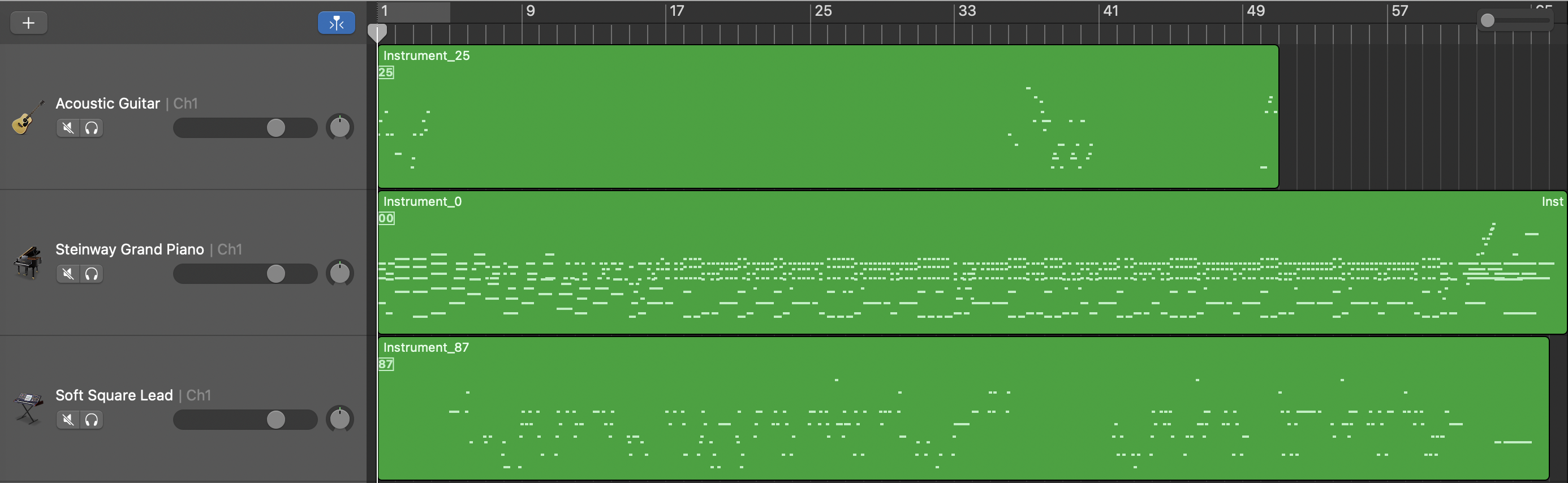

Length and Structure Conditioned Model



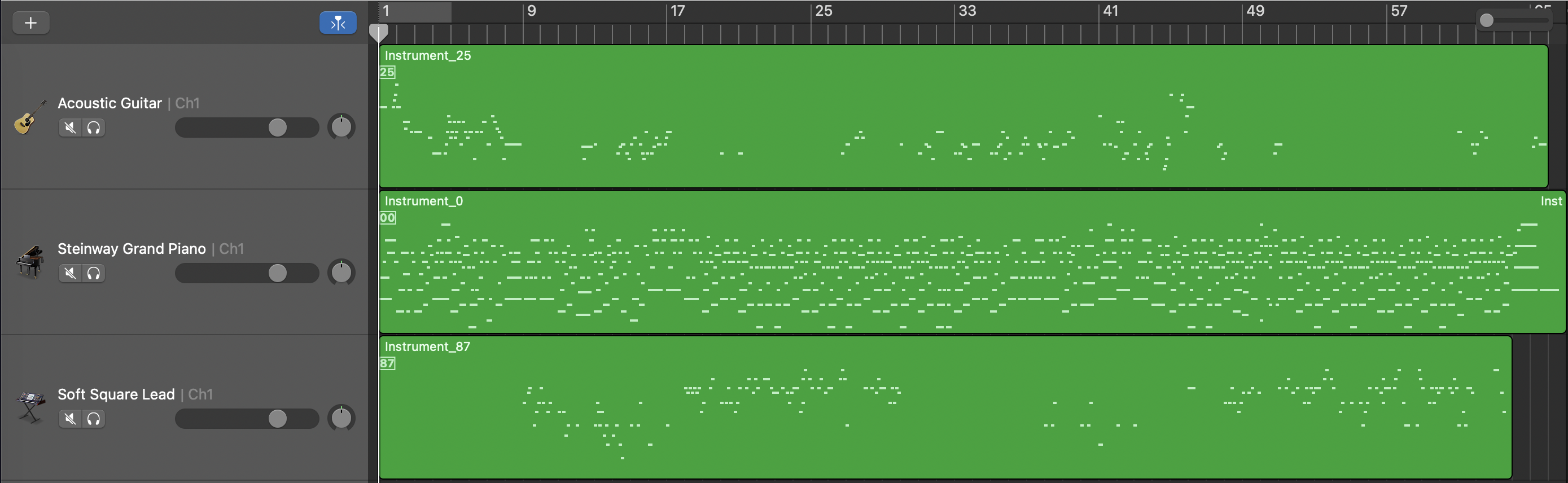
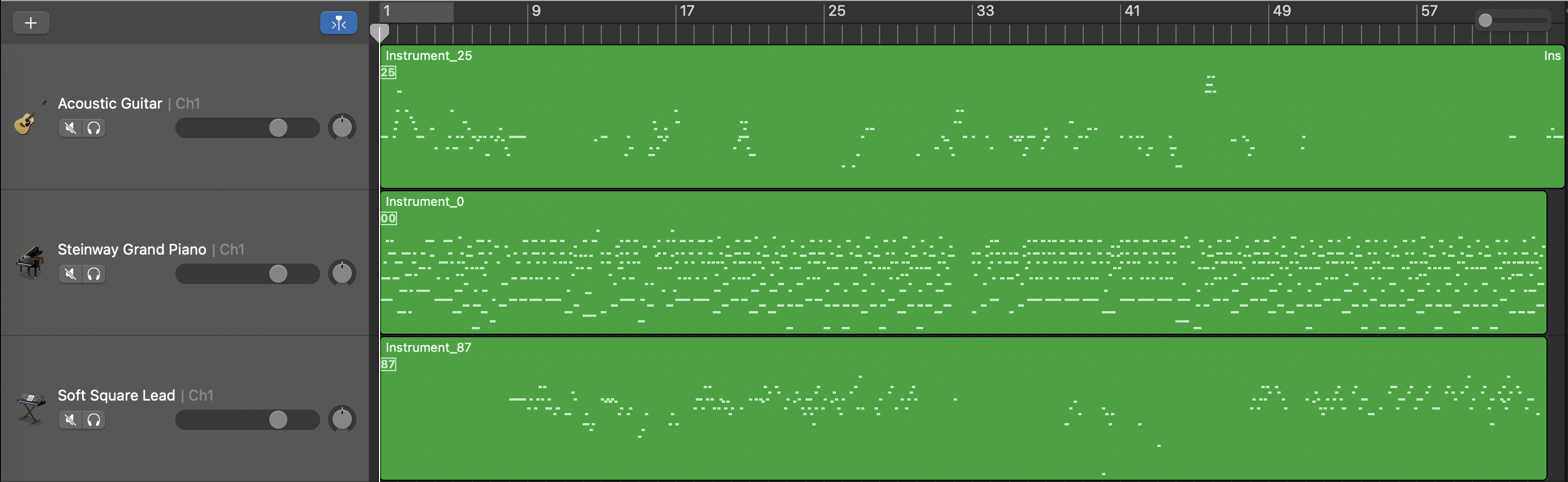

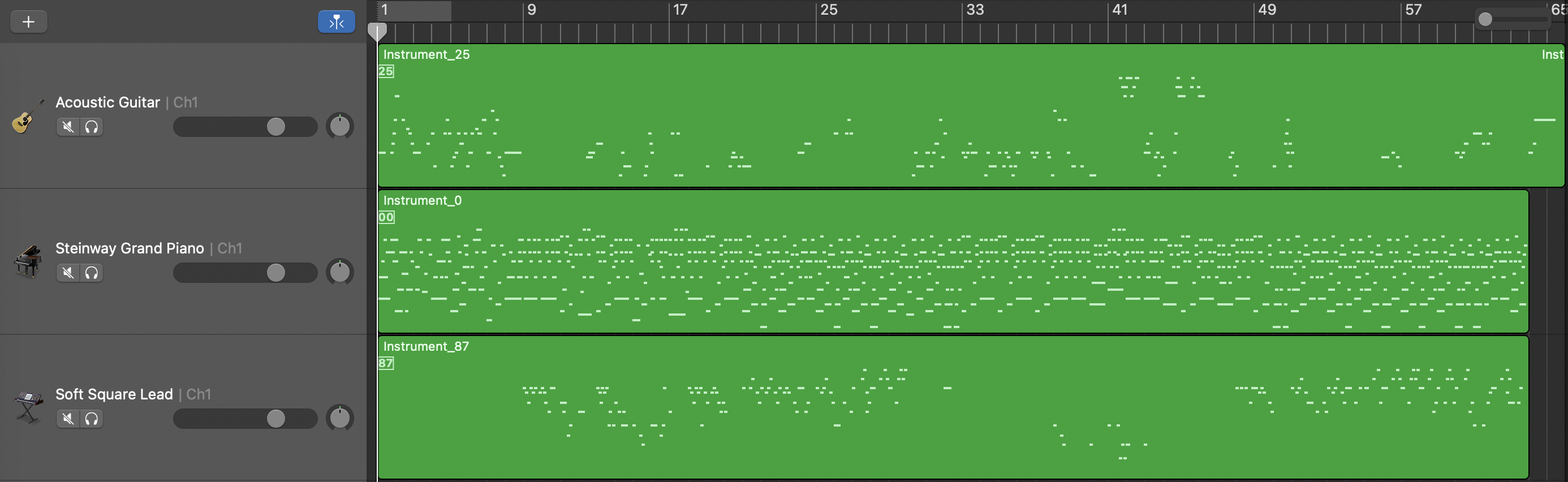
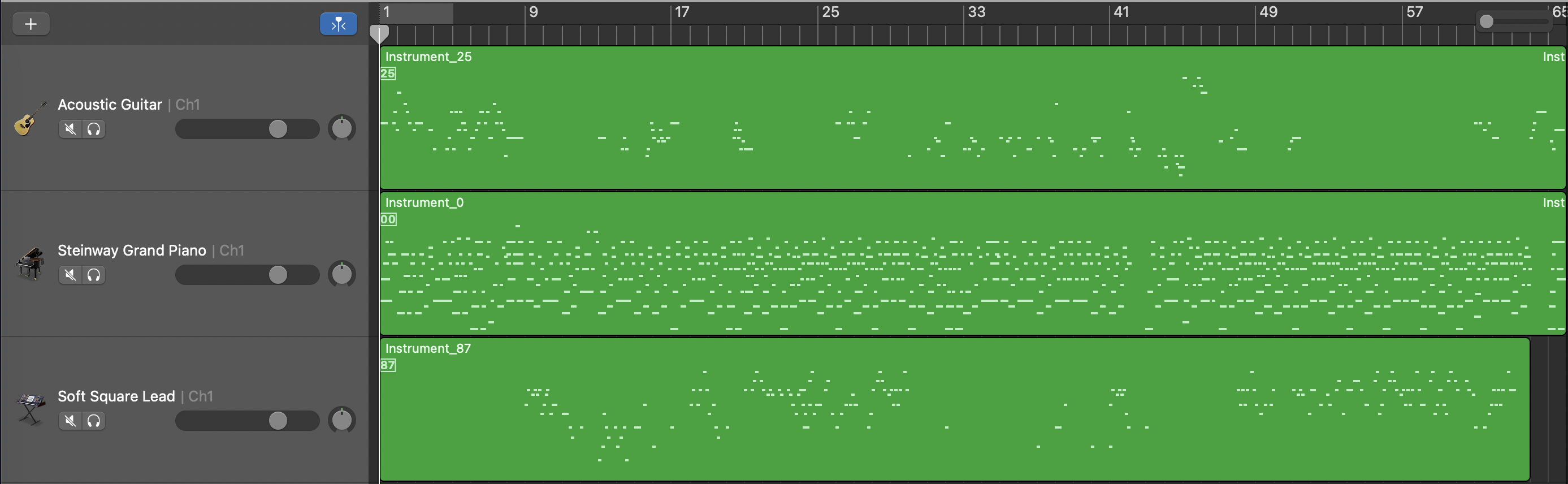
Quality Showcase
Below are some representative results to showcase the generation quality.
Piano Track’s Textures

Classic arpeggiated patterns, resolving with a II–V–I progression.

Chord stabs with a syncopated bass, and occasional fast arpeggios to drive the momentum forward.

A semi-arpeggiated pattern with an embedded counter-melody, forming an intricate texture, punctuated by short block-chord stabs for surprise.
Intro
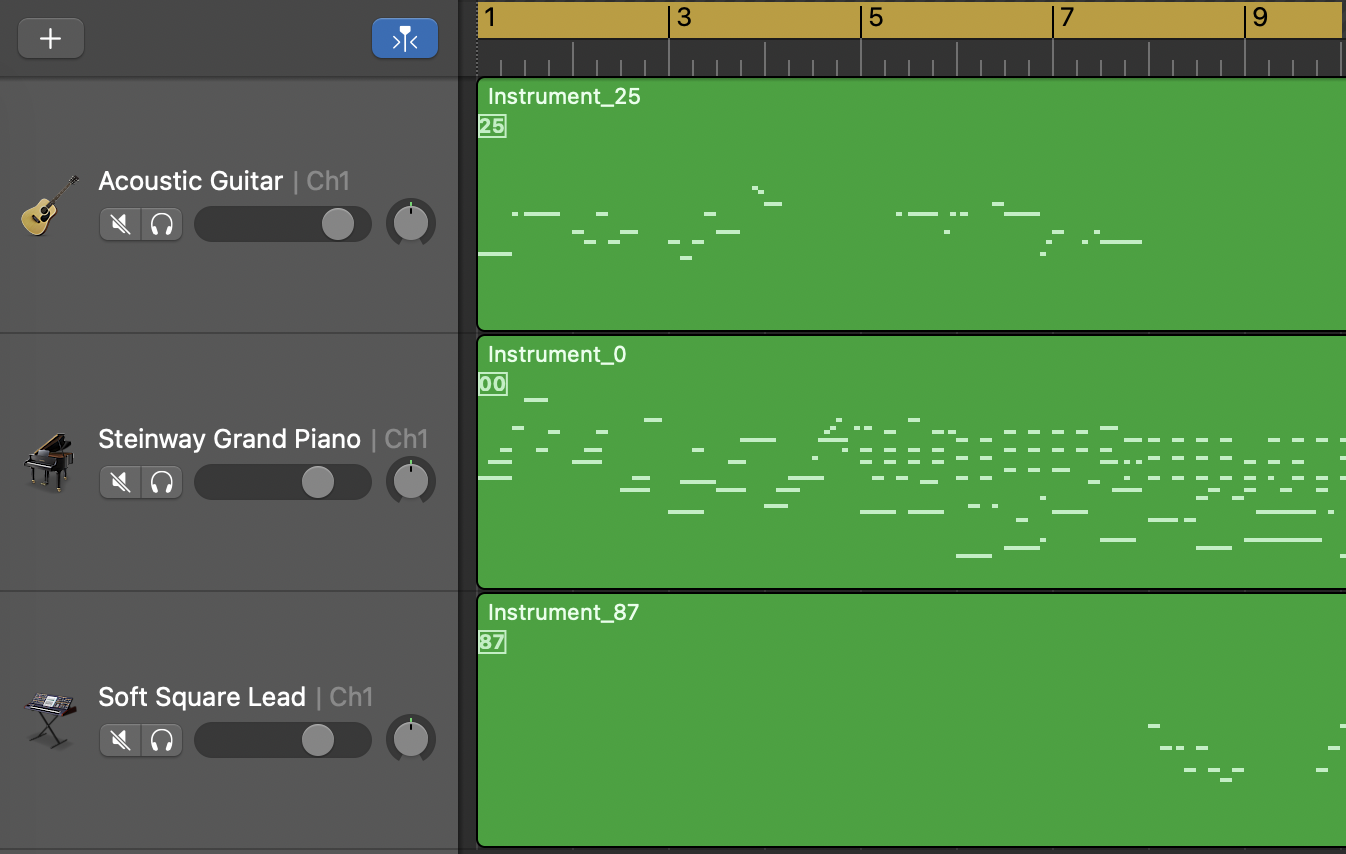
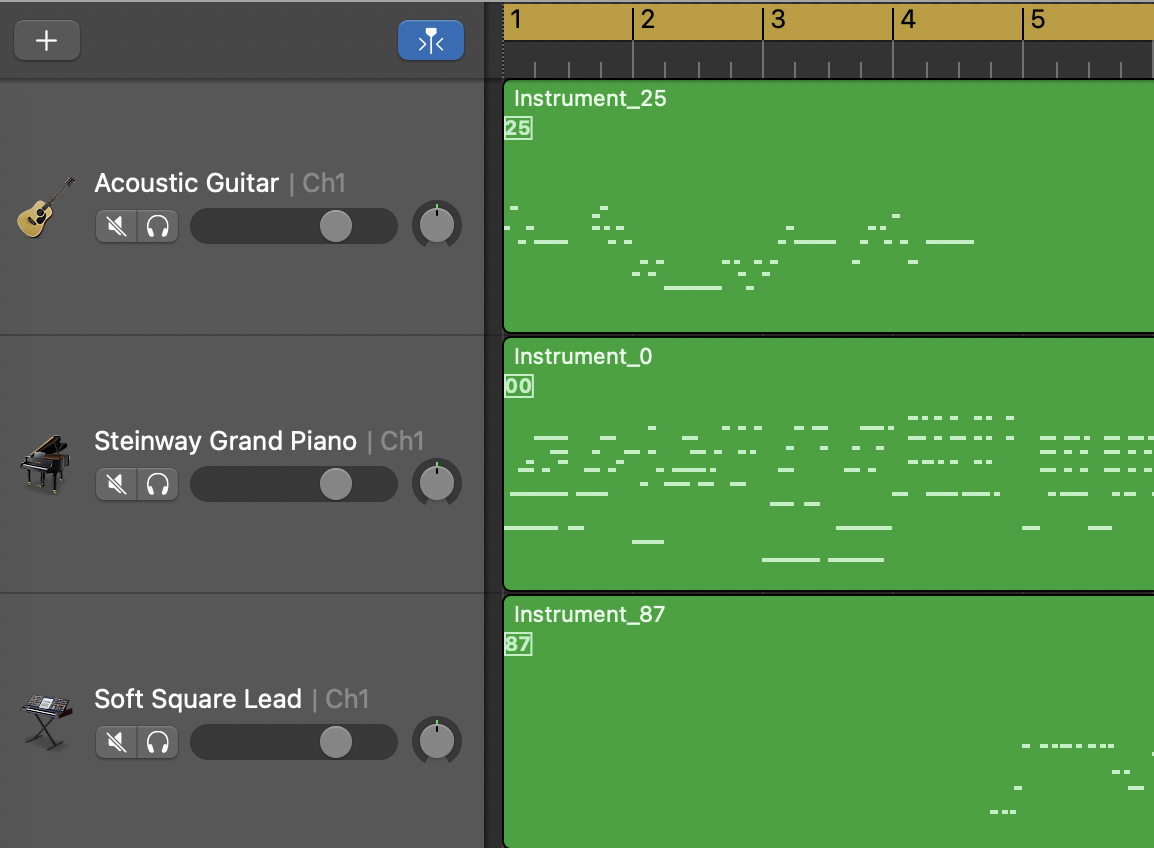
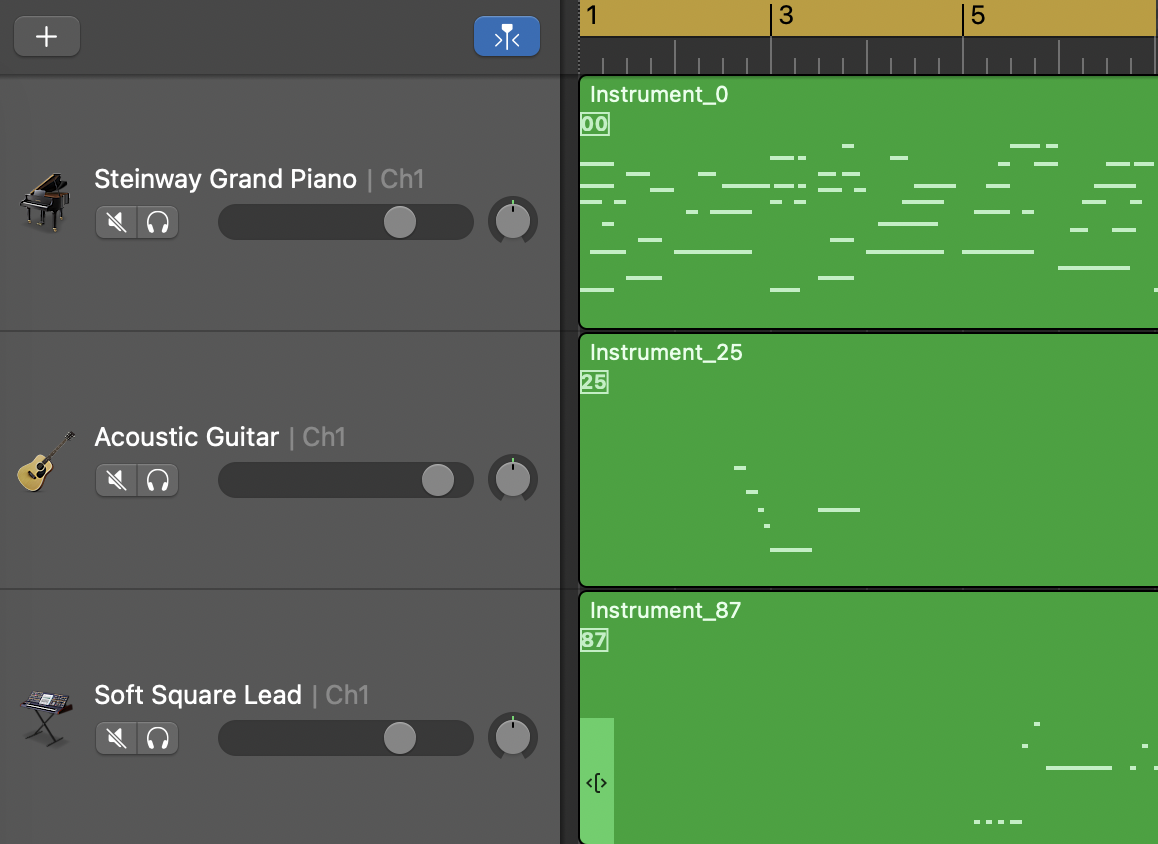
Outro
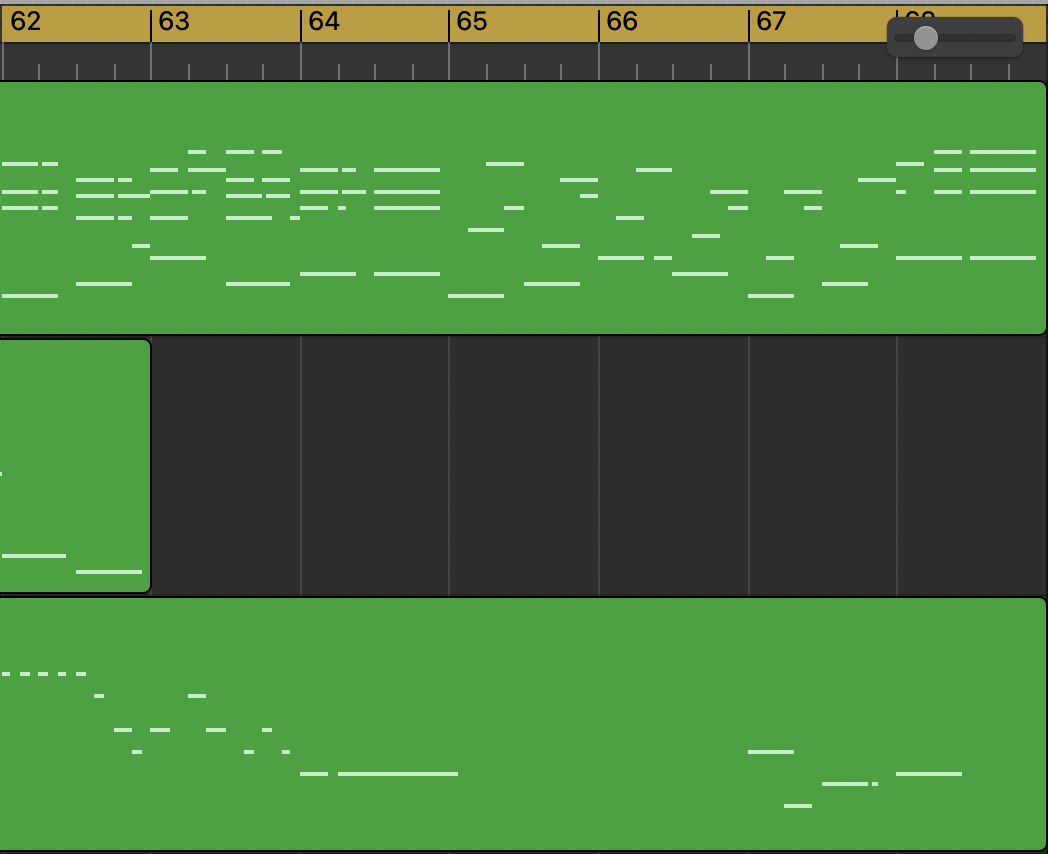

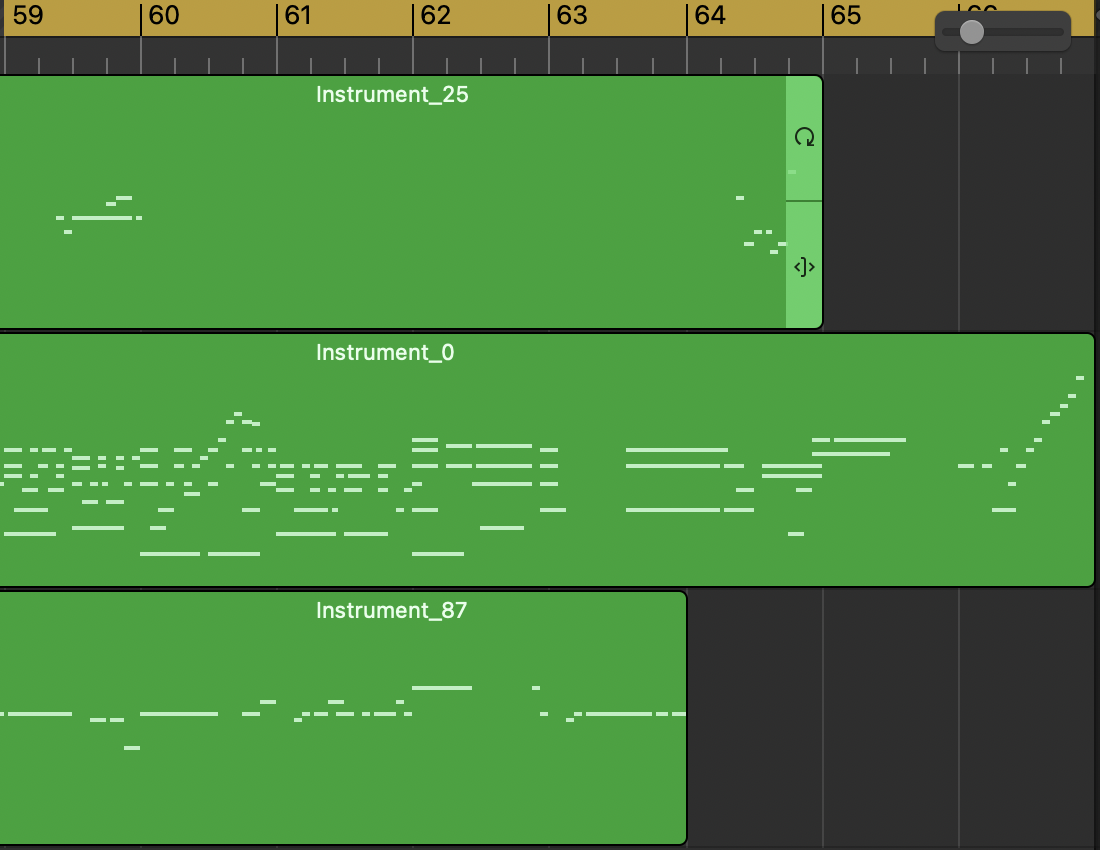
Interlude

VAE results
Interpolate
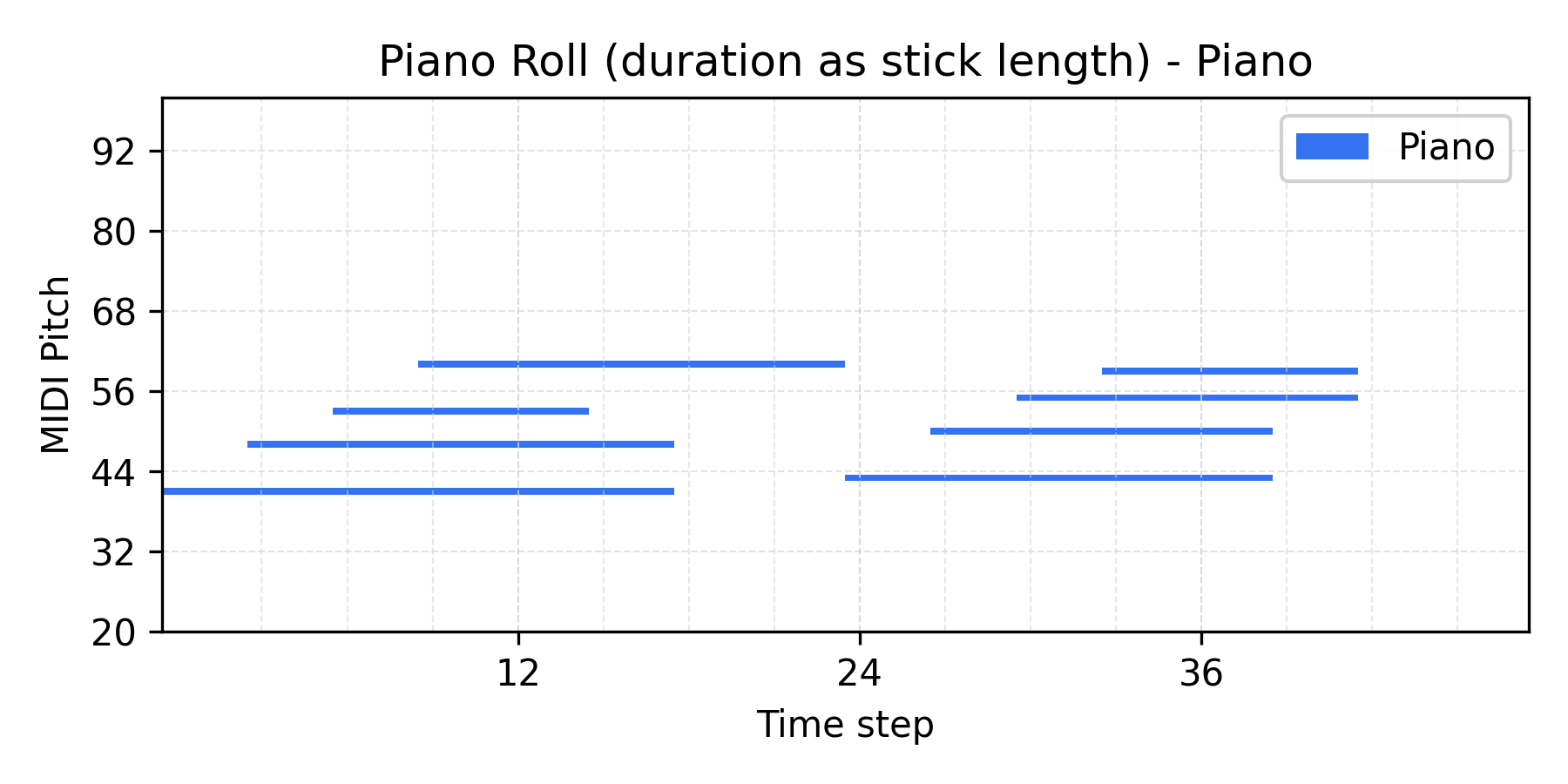
α = 0.0
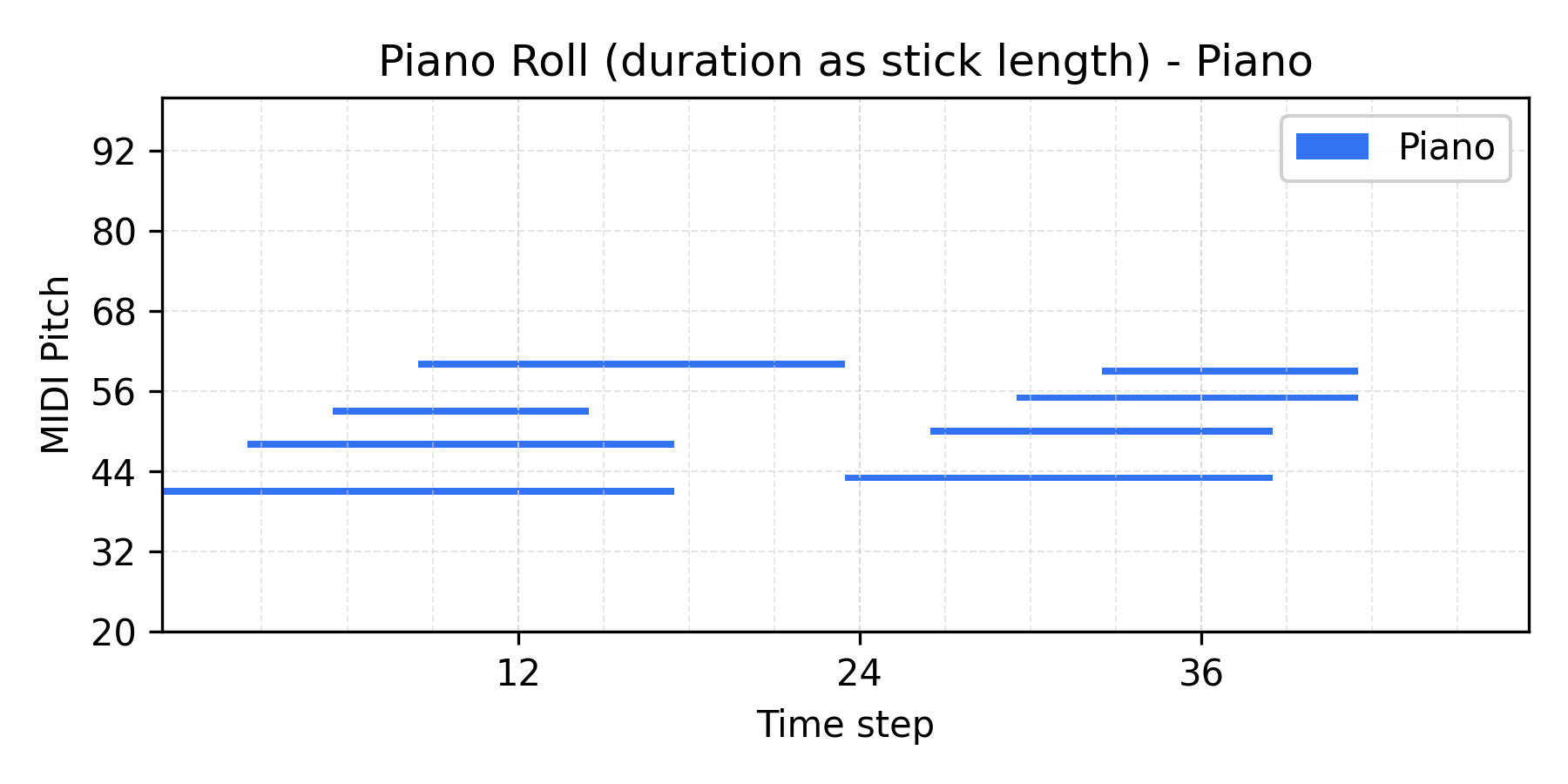
α = 0.3
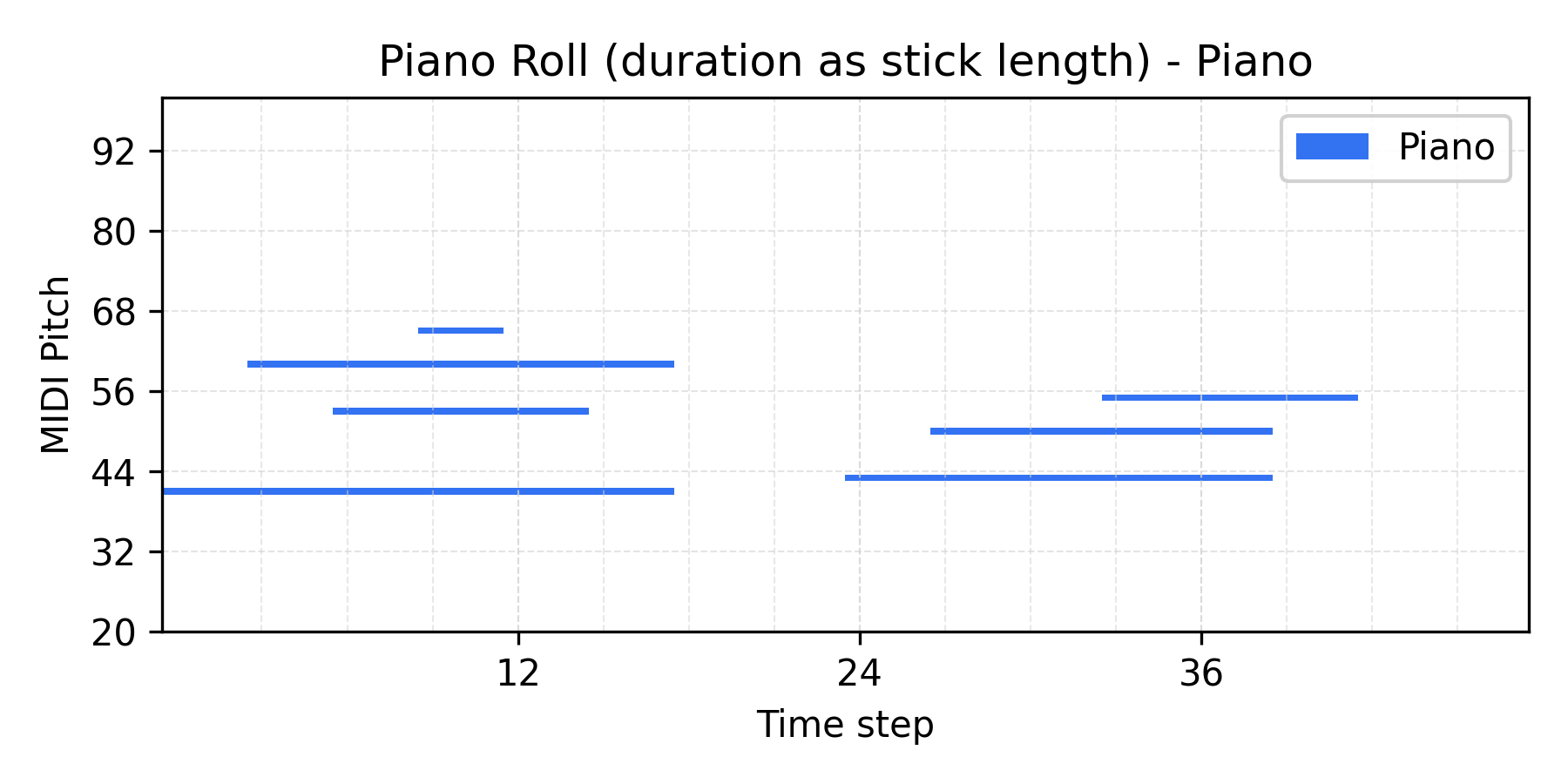
α = 0.4
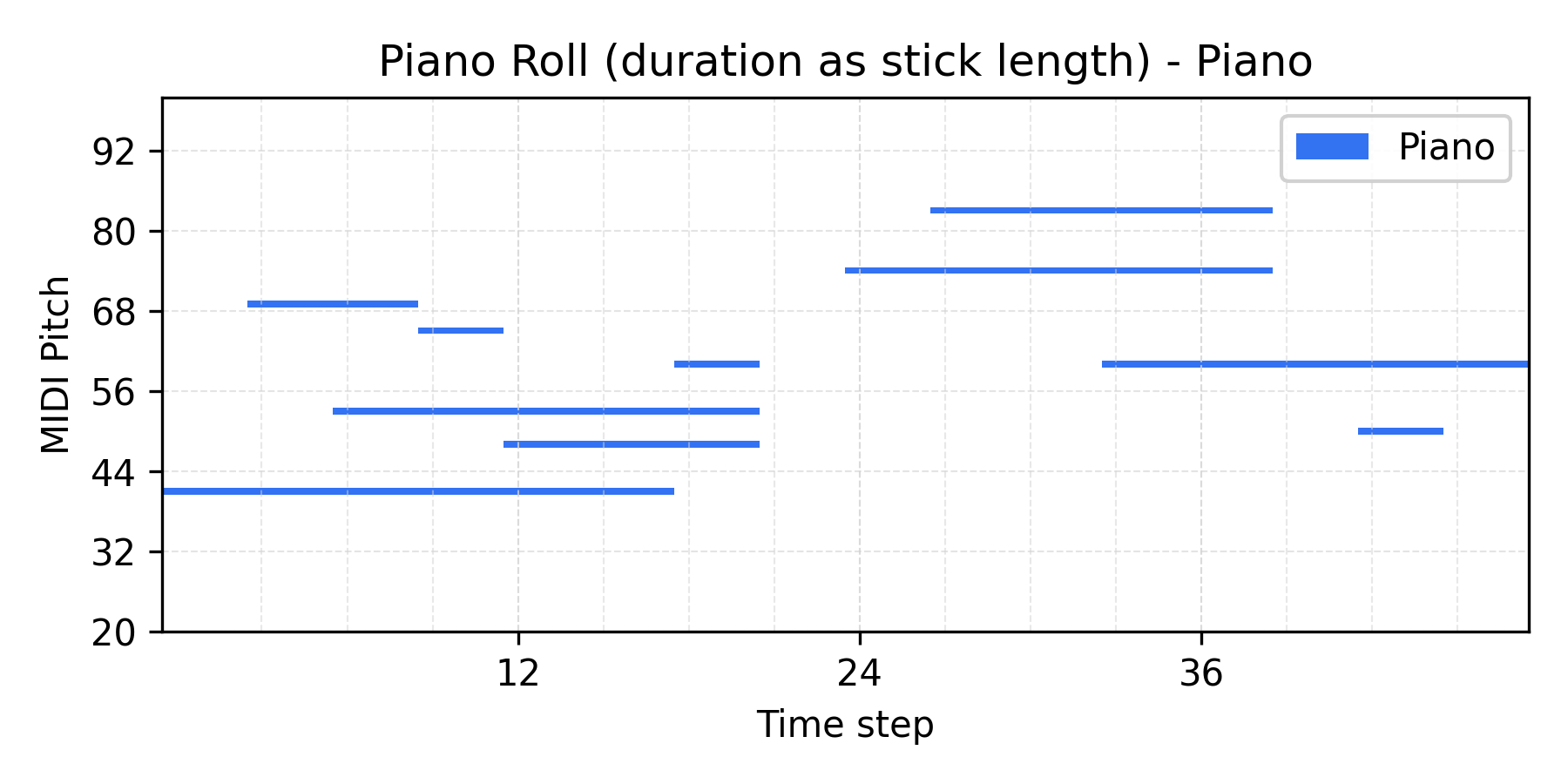
α = 0.5
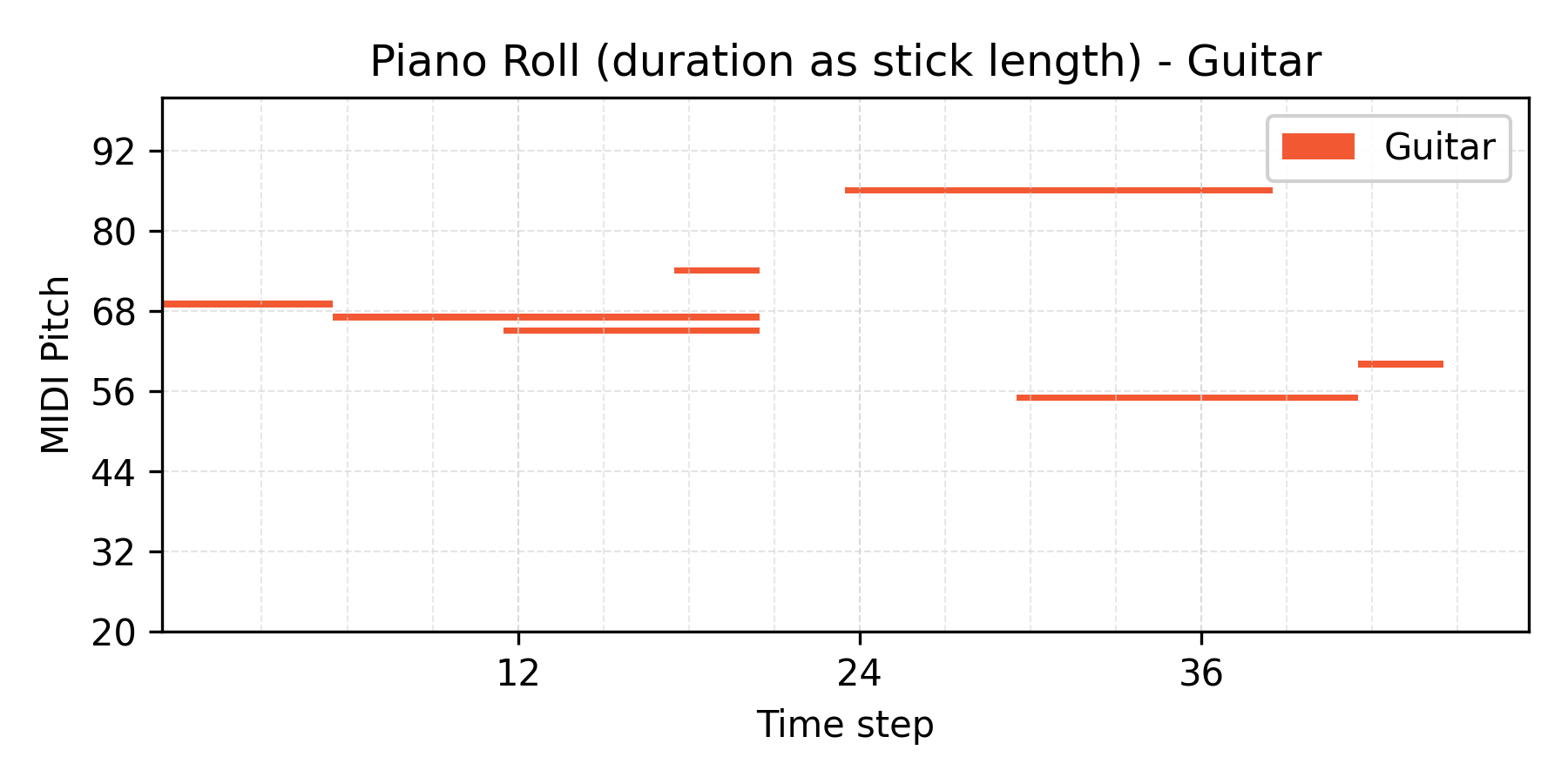
α = 0.6
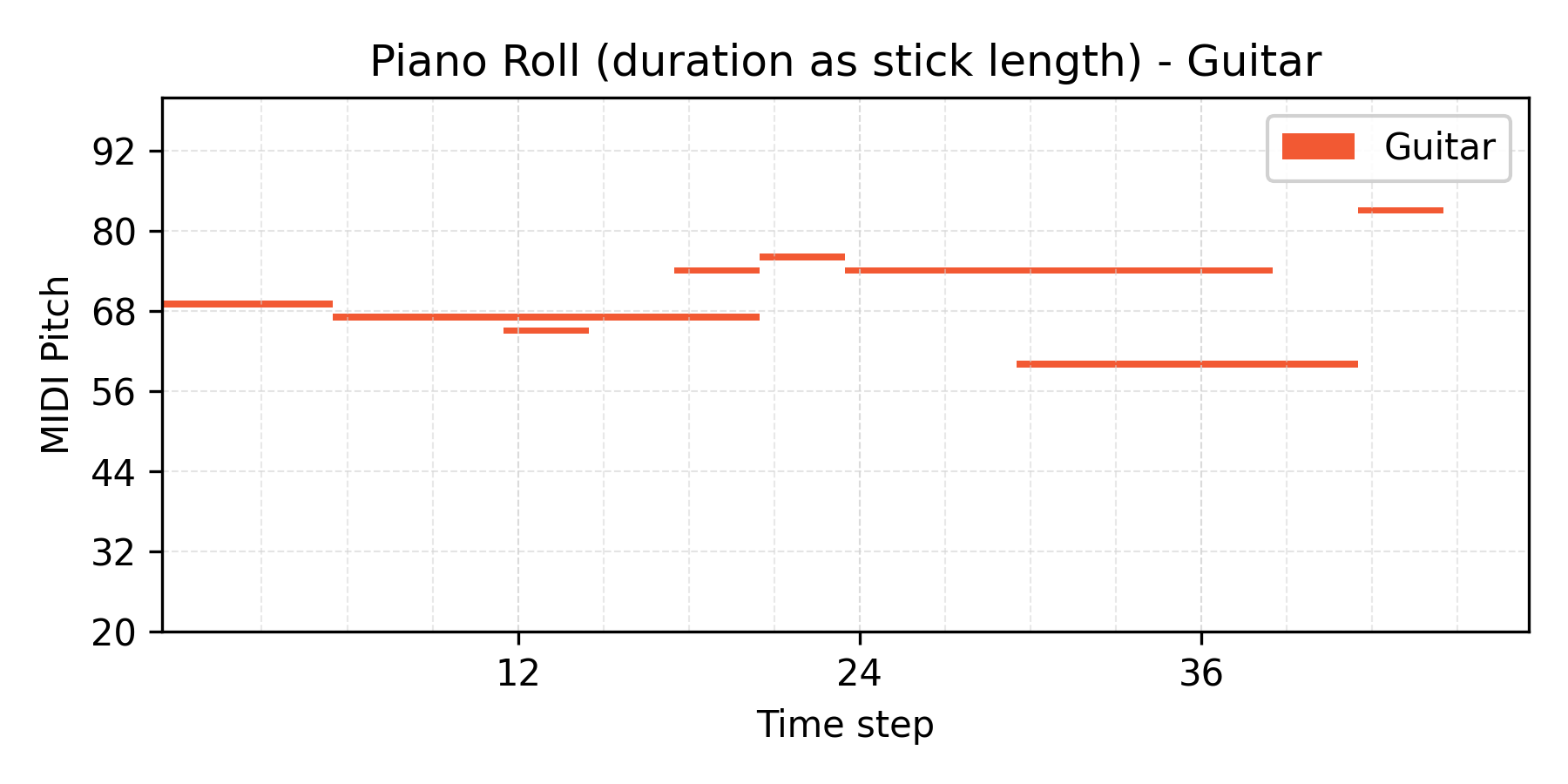
α = 0.7
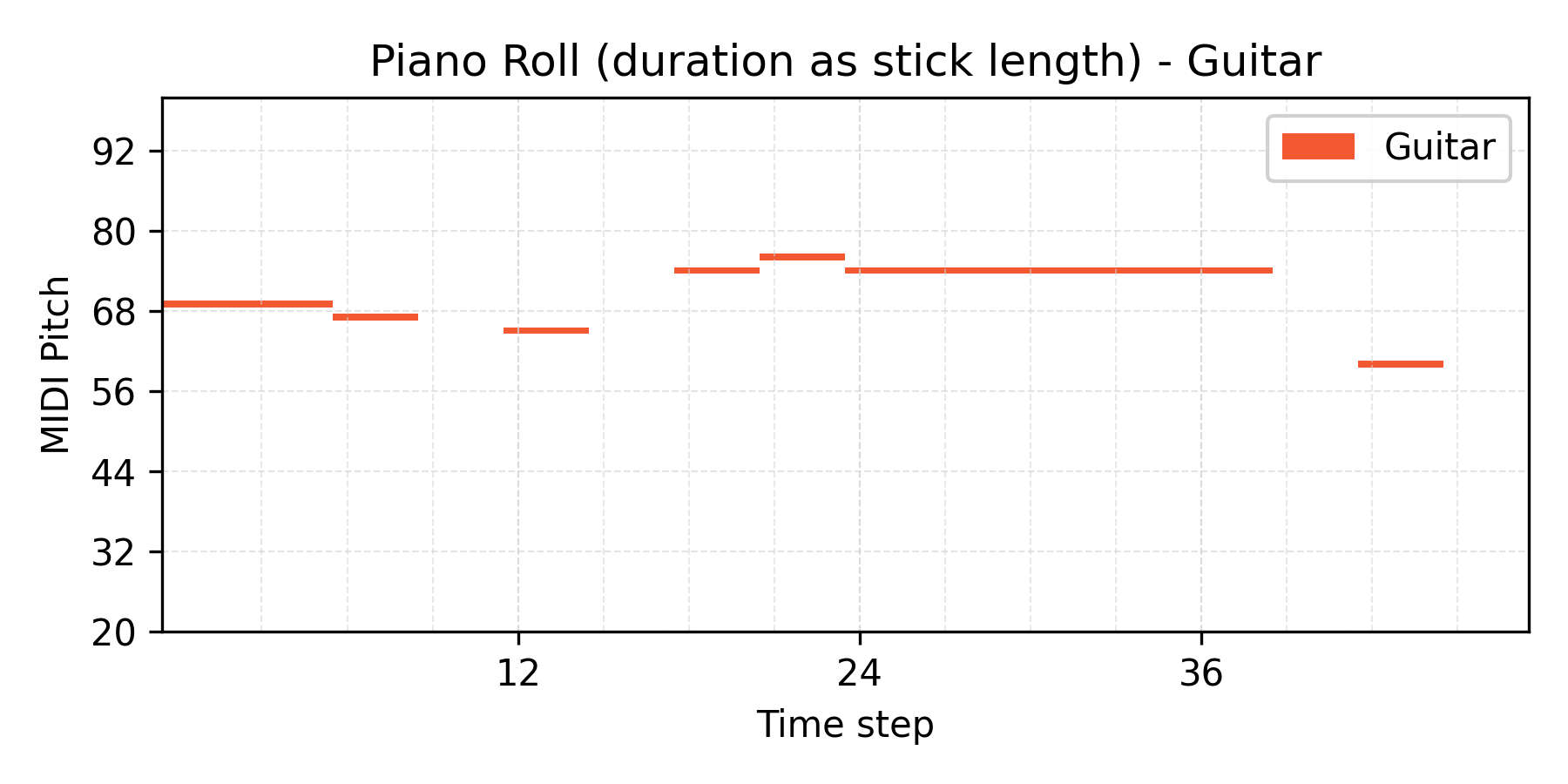
α = 0.8
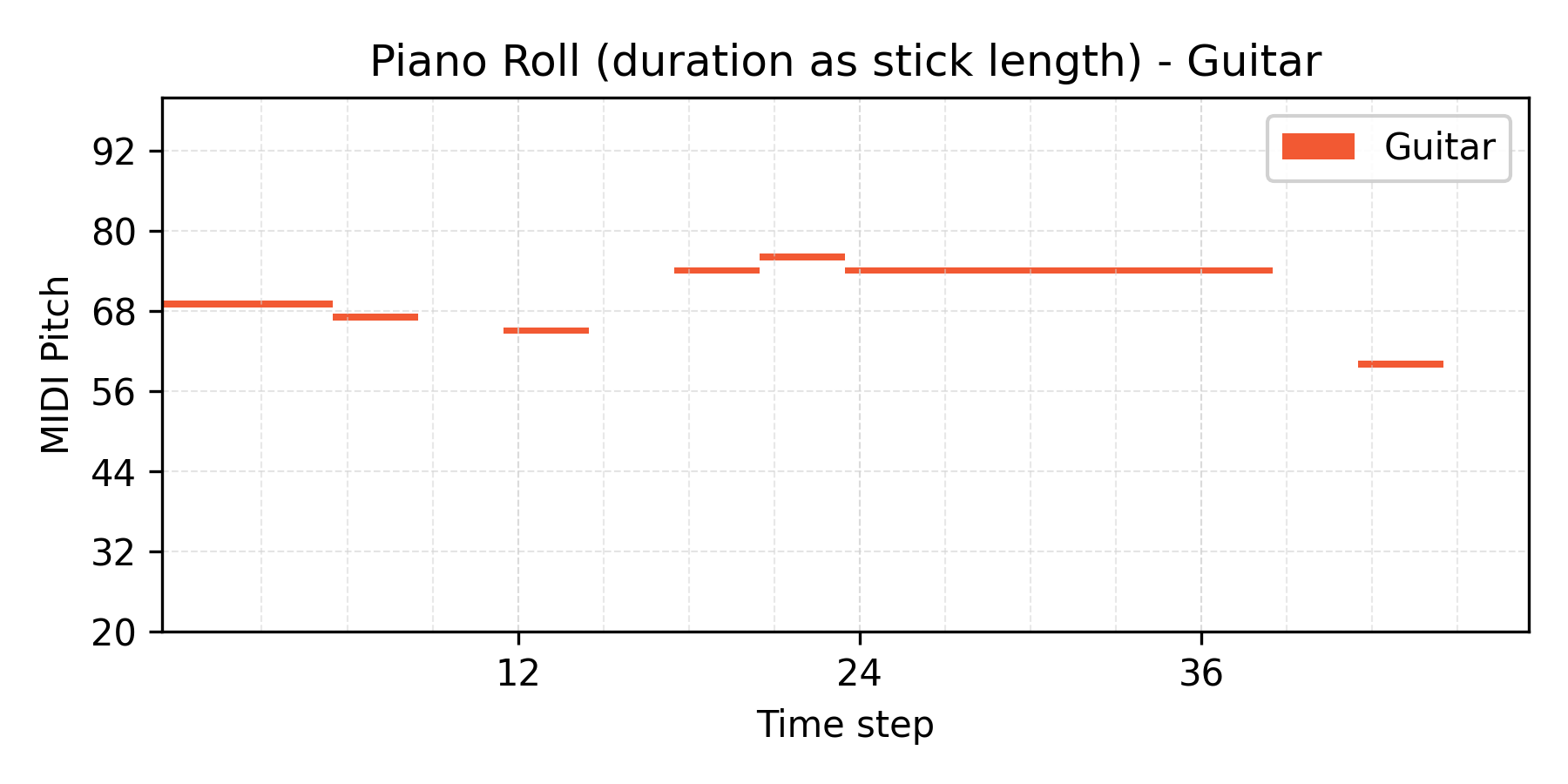
α = 1.0
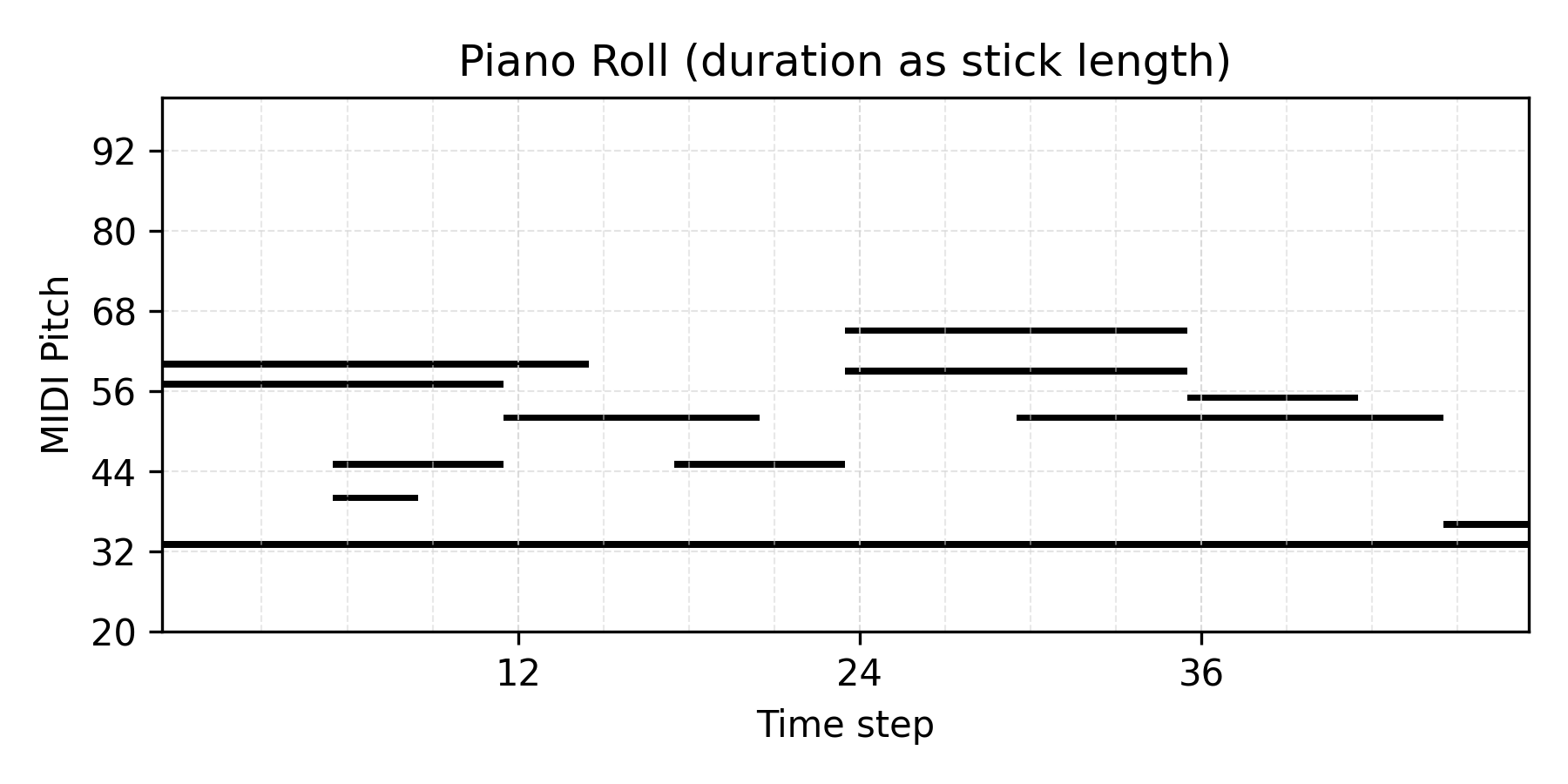
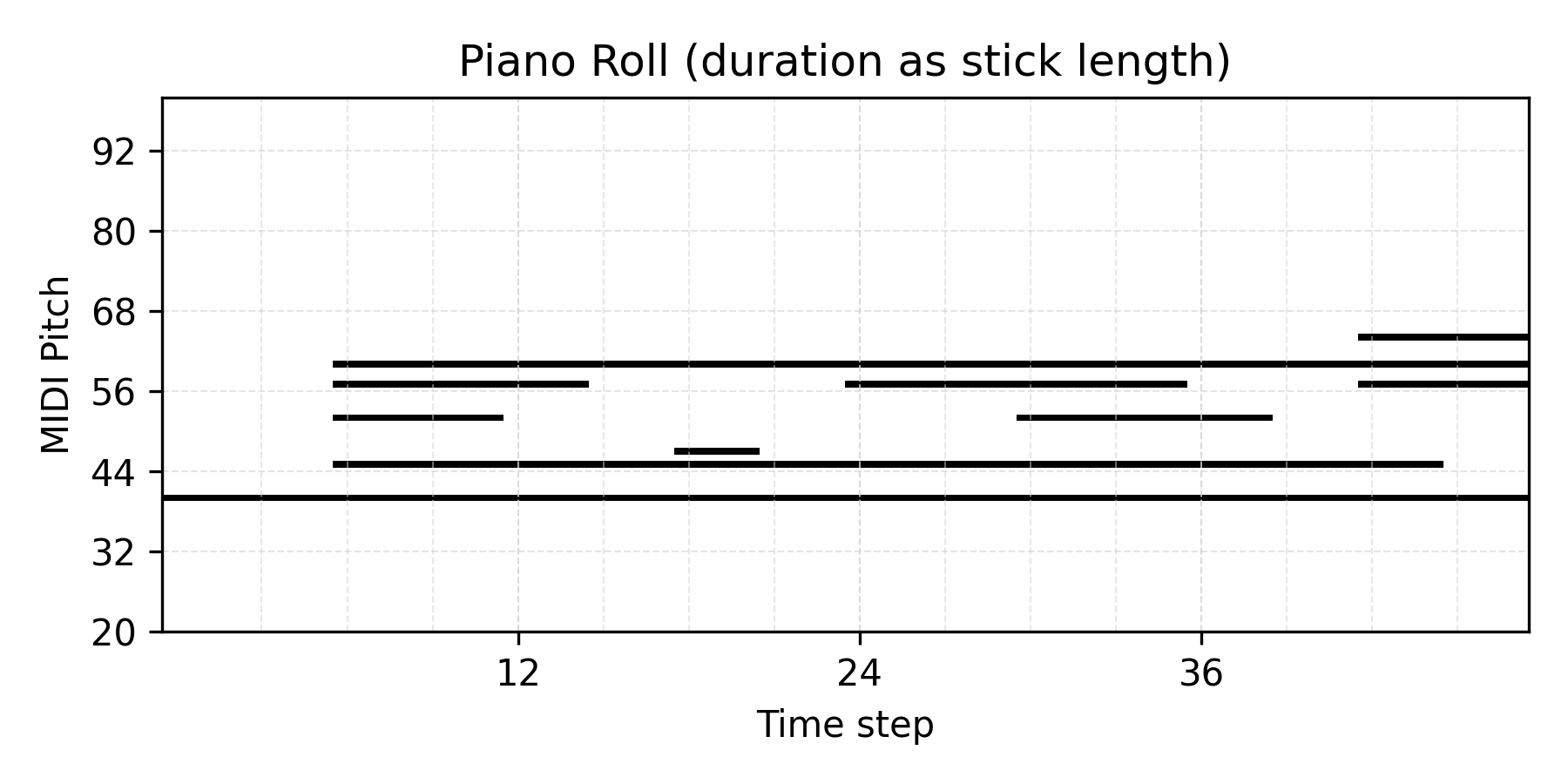
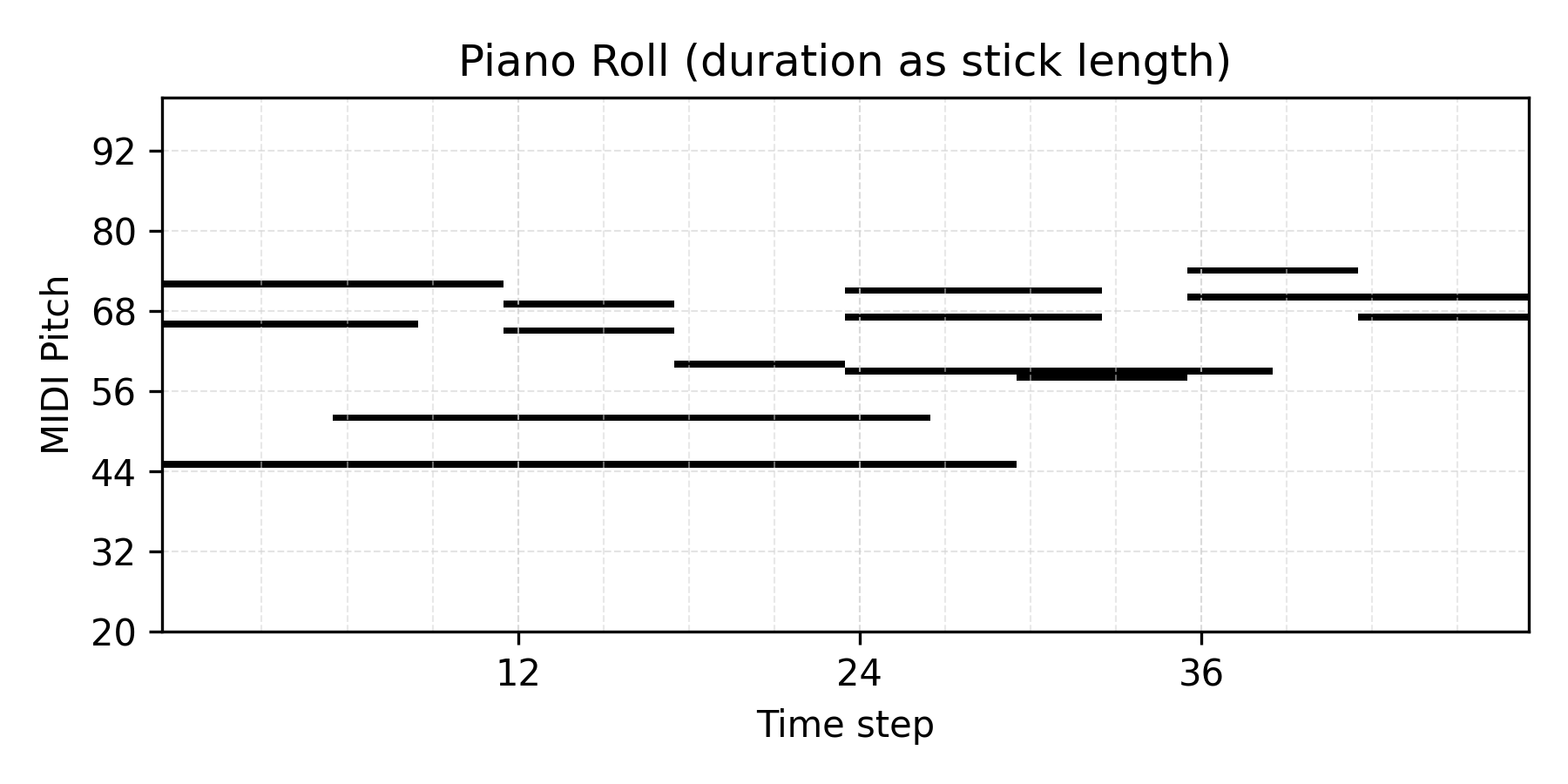
Prior Sampling
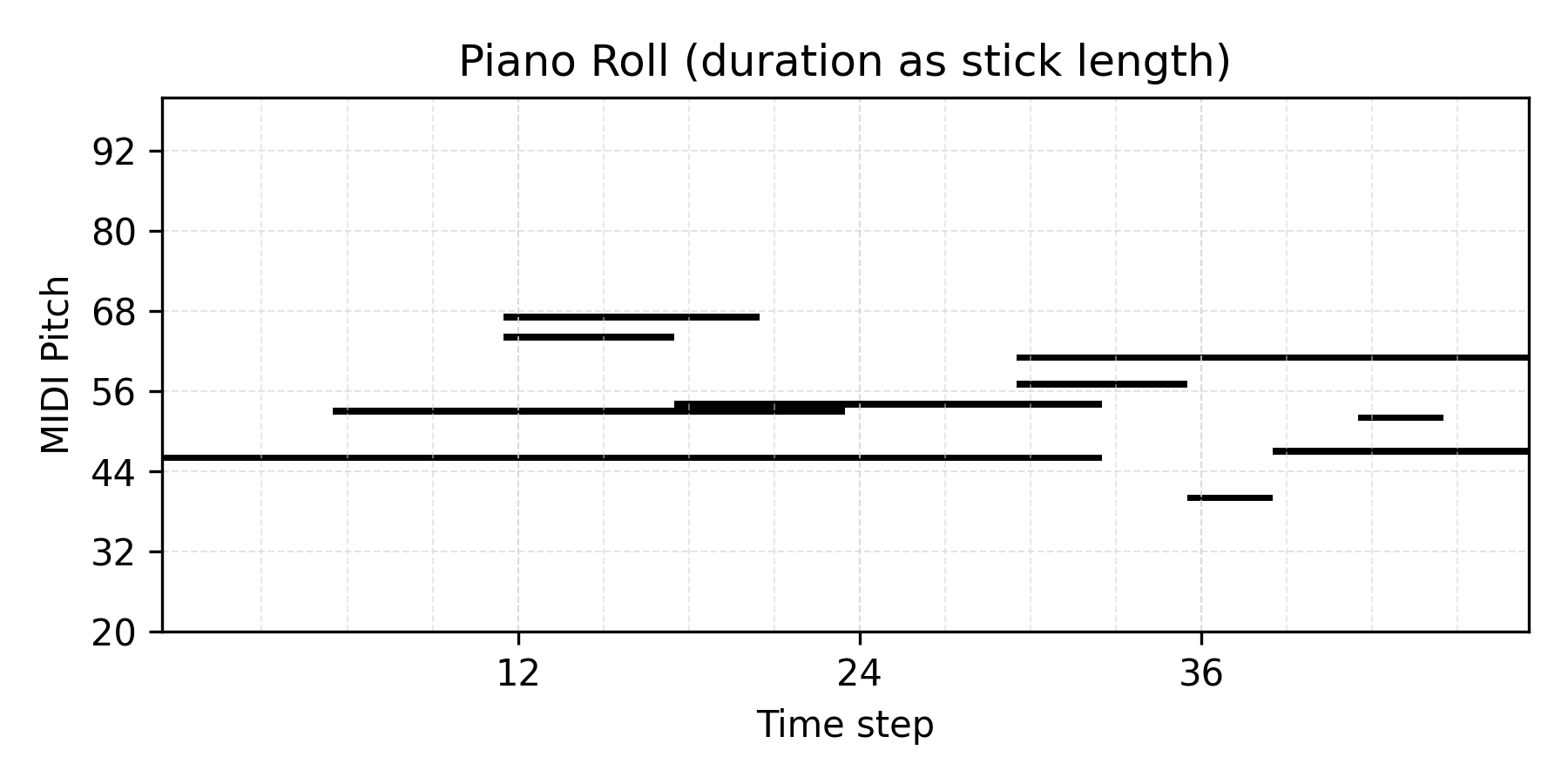
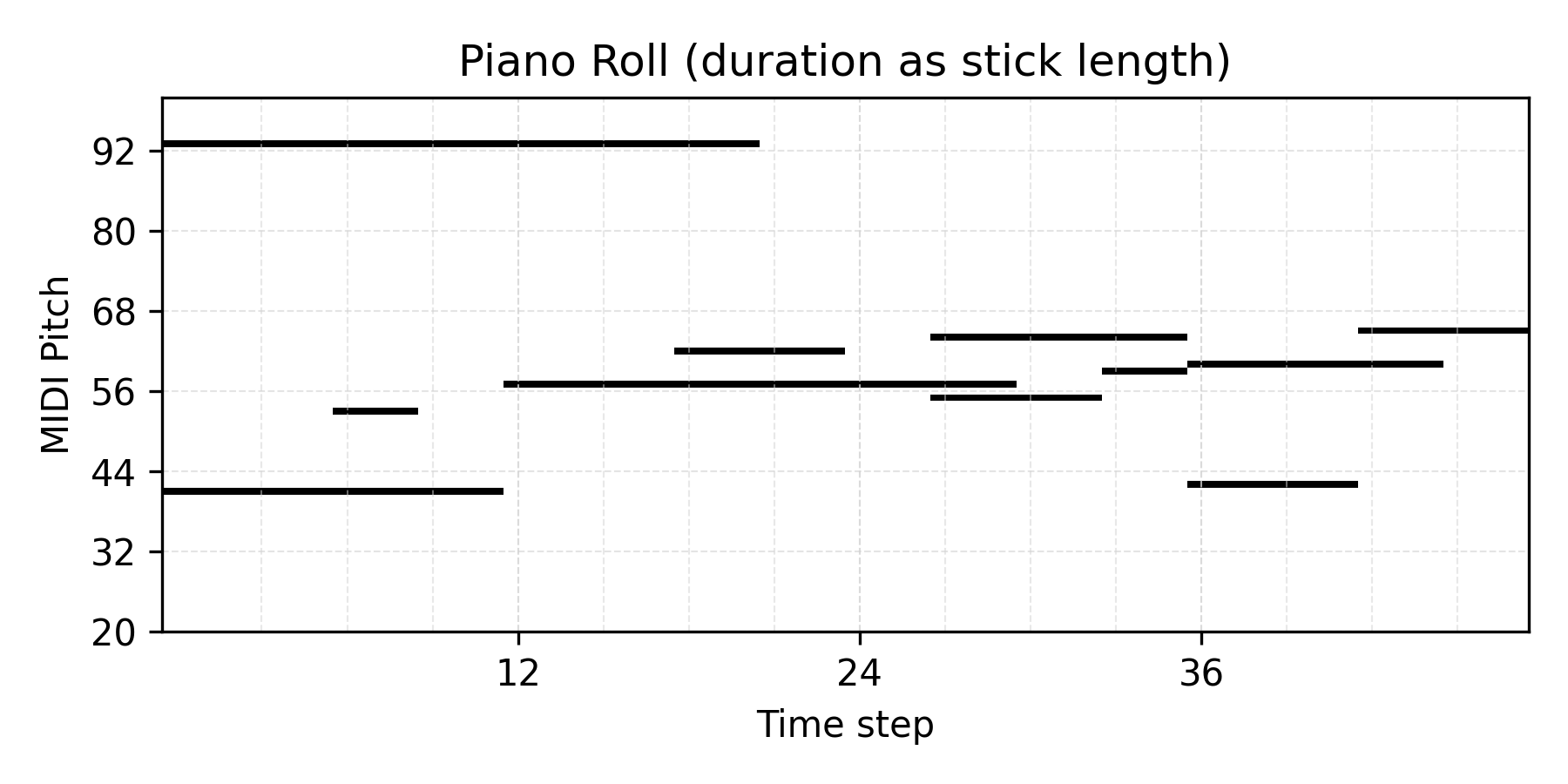
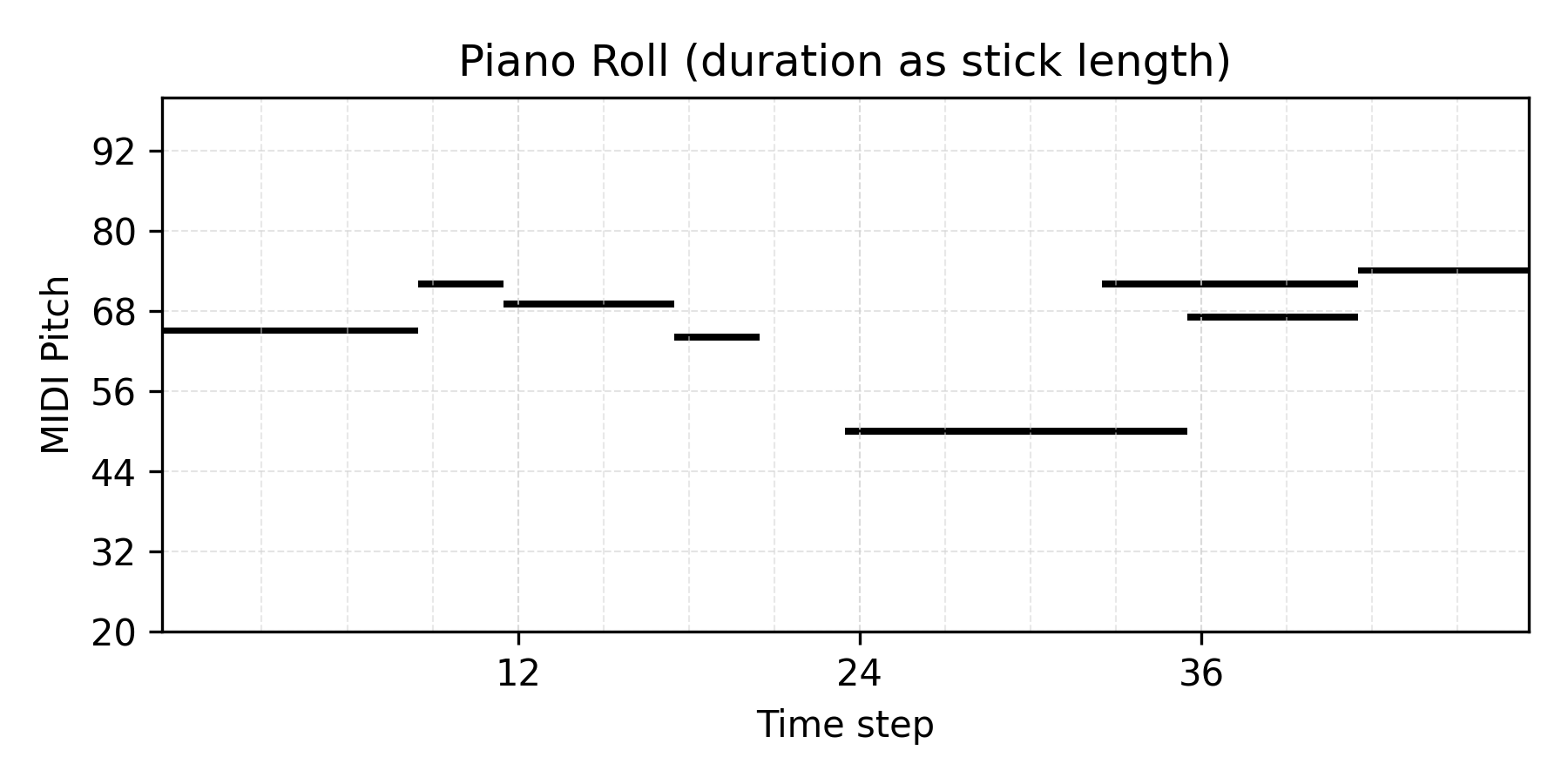
Citation
@article{ou2025phrasevae,
title={PhraseVAE and PhraseLDM: Latent Diffusion for Full-Song Multitrack Symbolic Music Generation},
author={Ou, Longshen and Wang, Ye},
journal={arXiv preprint arXiv:2512.11348},
year={2025}
}